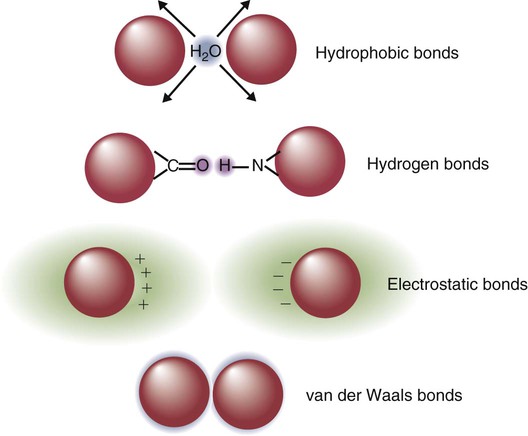
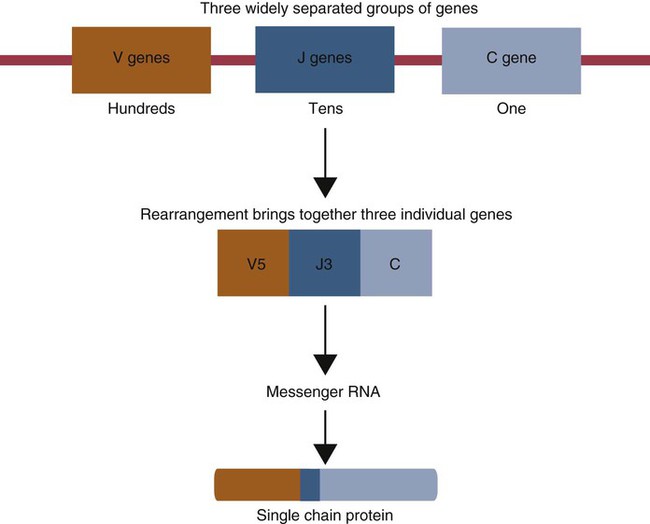
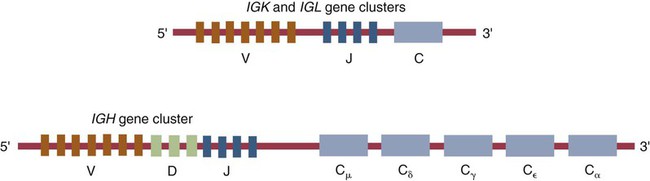
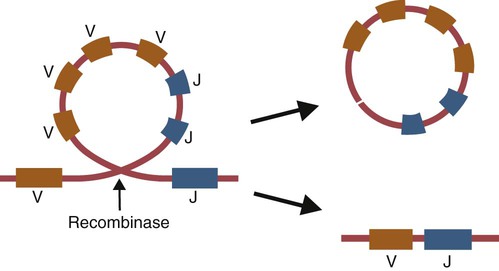
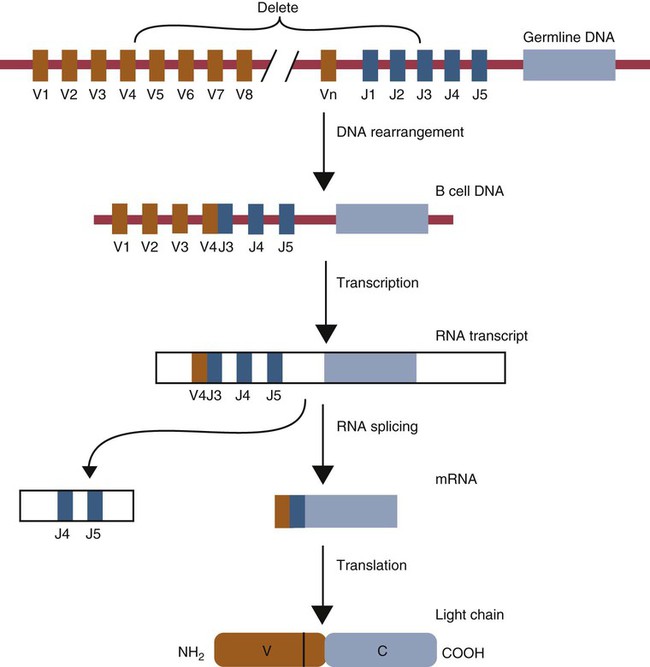
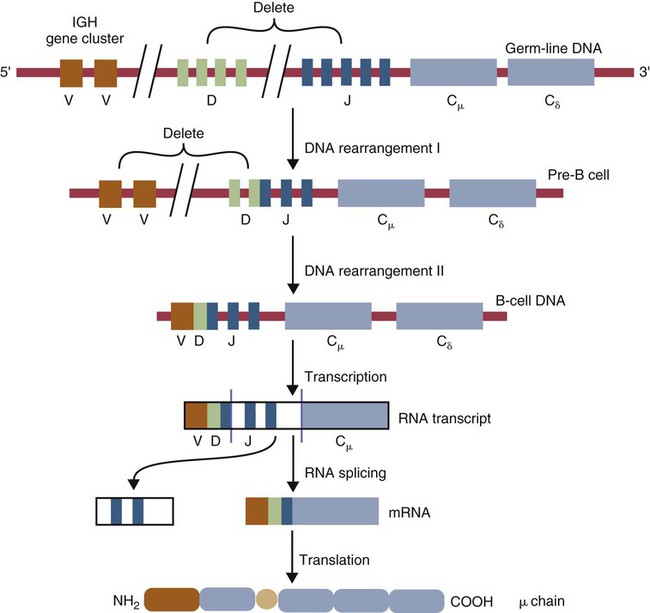
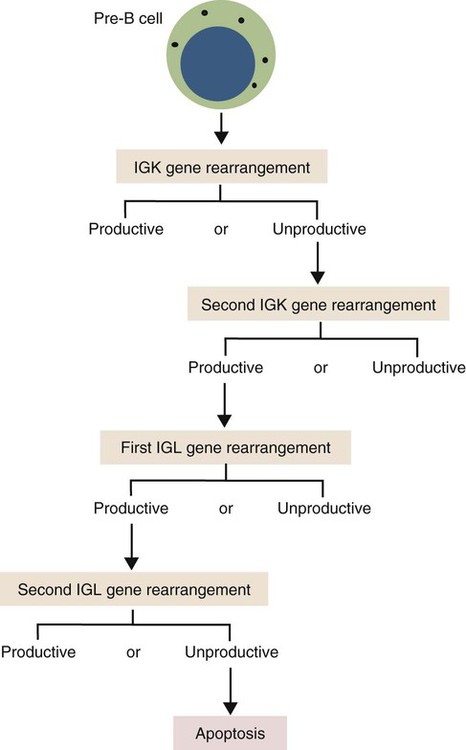
• Antigen molecules bind to a T cell receptor (TCR) or B cell receptor (BCR) when their shape matches the conformation of the groove in the antigen-binding receptor. • The shape of the antigen-binding groove depends on the sequence of the amino acids that line the groove. The sequence of these amino acids depends on the genes encoding the variable domains of the receptor. • Because of the ways by which nucleotide sequences can be rearranged in these genes, an enormous number of different BCRs and TCRs can be generated. • In some mammals, variable regions may be constructed by means of gene recombination. Different genes selected at random from a large library are joined to generate great sequence diversity. • In other mammals, receptor diversity is generated by gene conversion. Small blocks of donor nucleotides are inserted into V-region genes to generate sequence changes. • The genes coding for antigen-binding sites in BCRs, but not TCRs, also undergo random somatic mutation, resulting in even more sequence changes. • These mechanisms collectively enable an animal to make the millions of different receptors that can bind to almost all foreign antigens. The major bonds formed between an antigen and its receptor are hydrophobic (Figure 17-1). When antigen and antibody molecules come together, they exclude water molecules from the area of contact. This frees some water molecules from constraints imposed by the proteins and is therefore energetically stable. (The bond can be likened to two wet glass microscope slides stuck together. Anyone who has tried to separate two wet glass slides can confirm the effectiveness of this type of bonding.) Multiple genes code for each receptor peptide chain. Several genes code for each variable region, whereas only one codes for a constant region. As a result, the single constant-region gene can be combined with any one of several different variable-region genes to make a complete receptor chain (Figure 17-2). Instead of having genes for all possible receptor chains, it is only necessary to have genes for all the variable regions and to join these to an appropriate constant-region gene as required. In addition, antigen receptor chains may be paired in different combinations to yield even greater diversity, a process called combinatorial association. Three gene loci code for immunoglobulin peptide chains, and each is found on a different chromosome (Figure 17-3). One locus, called IGK, codes for κ light chains; one, called IGL, codes for λ light chains; and one, called IGH, codes for heavy chains. In humans, heavy chain V regions are coded for by three genes, IGHV, IGHD, and IGHJ. The IGH locus contains about 90 different IGHV genes. Mouse IGH may have as many as 1500 different IGHV genes, but up to 40% of these are pseudogenes. The IGH locus also contains several IGHJ genes situated 3′ to the IGHV genes. Several short genes, called IGHD genes (D for diversity), are located between the IGHV and IGHJ genes (see Figure 17-3). In mice there are about 12 IGHD genes, and in humans there are at least 30. A large noncoding region separates the IGHJ genes from the IGHC genes. The IGHC genes consist of a series of constant-region genes, one for each heavy chain class and subclass, arranged in the order 5′-Cµ-Cδ-Cγ-Cε-Cα-3′ along the chromosome. Light chain assembly requires the combination of one V, one J, and one C gene. During B cell development, the intervening genes are looped out, excised, and discarded. The V and J genes have sites at each end that guide the cutting enzymes (Figure 17-4). The looped-out genes are chopped off, and the free ends of the DNA are rejoined so that the V and J genes form a continuous sequence. Two sets of enzymes are used in this process. Recombinases cut the DNA at two points, thus excising unwanted genes. Following this, DNA repair enzymes join the two free ends to reform a continuous sequence. If these enzymes are defective, antibodies (and TCRs) cannot be made. In foals with severe combined immunodeficiency, for example, there is a defect in the DNA repair enzyme that joins the cut ends. As a result, these foals cannot make either TCRs or BCRs and thus have no functional B or T cells (Chapter 37). Light chain gene recombination occurs in two stages. Randomly selected V and J genes are first joined to form a complete V-region gene. The joined V-J genes remain separated from the C gene until messenger RNA (mRNA) is generated. At that time the unwanted J genes are excised, and the complete V-J-C mRNA is then translated to form a light chain (Figure 17-5). When a heavy chain V region is assembled, its construction requires the splicing together of IGHV, IGHD, and IGHJ genes (Figure 17-6). This use of three randomly selected genes enormously increases the amount of variability. For example, if a pool of 100 V, 10 J, and 10 D genes are recombined, then 100 × 10 × 10 = 10,000 different V regions can be constructed. The recombination of these genes also occurs in a specific order. Thus IGHD is first joined to IGHJ, then V genes are attached to make a complete V-region gene. After transcription, any unwanted J genes are deleted, the C gene mRNA is attached, and the completely assembled V-D-J-C mRNA is translated to form a heavy chain. Although the random selection of genes from two or three different pools generates a large number of different combinations, not all of these combinations will produce usable antibodies. Some combinations may result in a nucleotide sequence that cannot be translated into protein. These are called nonproductive rearrangements. For example, nucleotides are read as triplets called codons, each of which codes for a specific amino acid. If the codons are to be read correctly, then the sequence must be in the correct reading frame. If nucleotides are inserted or deleted so that the codon reading frame is changed, the resulting gene may code for a totally different amino acid sequence. If this frameshift results in inappropriate splicing, translation is prematurely terminated. It is probable that nonproductive rearrangements are produced in two of three attempts during B cell development. When this happens, the B cell has several additional opportunities to produce a functional antibody. For example, immature B cells initially rearrange one of the IGK genes (Figure 17-7). If this fails to produce a functional light chain, they switch to the other IGK allele for a second attempt. If this does not work, the B cell will use one of the IGL alleles, and if this fails, the second IGL allele represents the last resort. If all these efforts fail to produce a functional light chain, the B cell cannot make a functional immunoglobulin. It will undergo apoptosis without participating in an immune response.
How Antigen-Binding Receptors Are Made
Receptor-Antigen Binding
Antigen Receptor Genes
Gene Recombination
IGH Locus
Generation of Junctional Diversity
Gene Rearrangement
Base Insertion
![]()
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


